In the previous article, we introduced the idea of using two weapons, the Kullback-Leibler information content (KL distance) and the graphical lasso, to detect the degree of abnormal price movements of individual stocks. In this article, we will actually derive the KL distance between two probability distributions using a model called the graphical Gaussian model.
By analytically calculating the KL distance here, we will be able to incorporate the model into codes such as Python. We will write about the practical part in the next article.
Graphical Gaussian Model
To begin with, what is a graph in graphical lasso? In this context, a graph is a tool for representing conditional dependencies among variables in a multivariate data set.
Definition of Graph
A graph G is defined by two sets V and E pairs. Where,
Set V of vertices (nodes): the basic elements of a graph, represented as points. Each vertex represents a specific element or object in the graph.
Set E of edges: represented as a line connecting two vertices, indicating a relationship or connection between vertices. An edge can be either directed (indicated by an arrow, with direction) or undirected (just a line, without direction).
This graphical model is called the Graphical Gaussian Model (GGM), especially when the dependencies among variables are estimated using a multivariate normal distribution.
Graph Creation and Meaning in GGM
Use of precision matrix: In GGM, the relationship between variables is represented using a precision matrix (the inverse of the covariance matrix). Each element of this matrix indicates the strength of the relationship between the two corresponding variables.
Interpretation of the relationship: If the elements of the precision matrix are non-zero, it means that there is a direct relationship between the two variables and they are connected by edges on the graph. If the element is zero, it is interpreted as no relationship and no edges are drawn.
Data Structure Visualization: This graph can be used to visualize complex relationships between variables in a data set. For example, if a variable is related to many other variables, it will have many edges and can be interpreted as likely to play an important role in the data.
Multivariate Normal Distribution in GGM
The multivariate normal distribution is generally expressed in the form N(μ,Σ), but in the GGM framework it may be expressed as N(x∣μ,Λ−1) using the precision matrix Λ.
In particular, if the mean is a zero vector, the probability density function of the multivariate normal distribution becomes
p(x)=(2π)k∣Λ−1∣1exp(−21xTΛx)
The use of precision matrices is often used in contexts such as graphical models because direct dependencies between variables are more clearly represented.
Analytically derive KL distances between variables in GGM
Here is where we start.
Let zi be a vector of other variables on the vector x except for the variable xi. Since the conditional distribution of xi given the probability distribution of zi is our interest, we evaluate the KL distance between pA(xi∣zi) and pB(xi∣zi) by the distribution pA(zi). (ETH, SOL, BNB, ARB..... measure the distance between the probability distribution of BTC's price movement at two points given pA(zi))
First, the accuracy matrix Λ and its inverse variance-covariance matrix Σ are divided as follows.
Λ=(LAlAlA⊤λA),Σ≡Λ−1=(WAwAwA⊤σA)
Find the distribution of P(xi∣zi).
If x is an M-dimensional vector, then zi is M−1-dimensional. Since the normal distribution divided by the normal distribution is a normal distribution, only the terms related to xi need to be expanded within exp.
By interchanging A and B, diBA can be obtained as well.
I referred to Detecting Correlation Anomalies by Learning Sparse Correlation Graphs for the derivation. However, in the original paper, the sign of the first term is reversed, which I think is an error on the part of the paper. If there are any errors in my derivation process, please let me know via Twitter or in the comments.
Now, how can the equation consisting of the three terms obtained here be viewed qualitatively? Using the GGM framework introduced in Chapter 1, each term can be interpreted as follows.
Term 1 - Anomaly Detection of Neighborhood Creation and Extinction:.
This measures how many other variables xi is related to a variable xi, i.e., the degree (number of direct connections) of that variable. A neighborhood is a collection of other variables that are directly linked to that variable. Since the number of nonzero elements in lA is the same as the degree of xi, this term serves as an indicator to detect changes in the neighborhood of xi, i.e., the creation of new connections or the disappearance of existing ones.
Term 2 - "closeness" of the neighborhood graph:.
This is the strength of the relationship between variables in the neighborhood of xi, i.e., how "tightly" connected are the edge weights in the graph. If xi has just one edge to another variable j, then this term is the difference in the correlation coefficient between xi and j divided by the precision λA or λB associated with xi. This measures how the strength of the correlations between variables varies.
Term 3 - Change in precision or variance of each variable:.
This term shows how the precision (or variance) of each variable changes rather than the change in correlation between variables. Precision is the inverse of variable uncertainty; the higher the precision, the lower the uncertainty. Therefore, this term is a measure that captures how the uncertainty of individual variables varies.
In essence, these three terms capture different aspects of the GGM to detect the relationships among variables, the closeness of those relationships, and how the uncertainty of individual variables is changing. Through these indicators, it is possible to quantitatively assess structural changes in the network, changes in the strength of the relationships between variables, and changes in the certainty of individual variables.
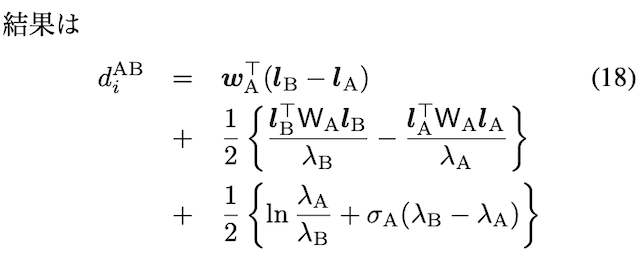
![Pair Trading with Graphical Lasso [Application]](/_next/image?url=https%3A%2F%2Fstorage.googleapis.com%2Fquant-talks%2Ftokyo.png&w=1920&q=75)